Learn more about updates regarding the 2024–2025 FAFSA process.
Academics
Admissions & Aid
Life at Pratt
Works
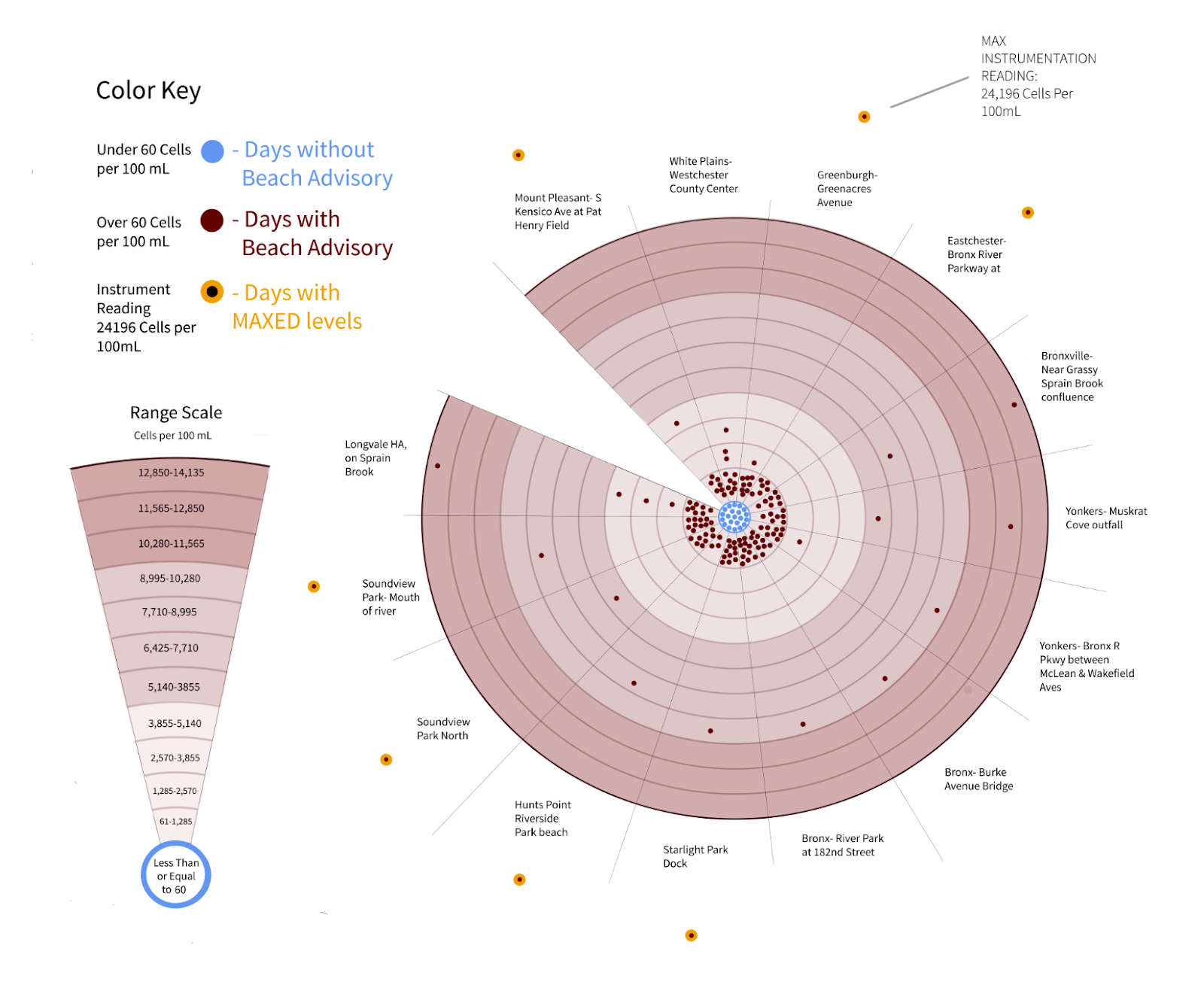
Bronx River Trash Collection and Fecal Material Analysis